

About a year ago, after looking at the resumes of engineers we had interviewed at TrialPay in 2012, I learned that strongest signal for whether someone would get an offer was the number of typos and grammatical errors on their resume. On the other hand, where people went to school, their GPA, and highest degree earned didn’t matter at all. These results were pretty unexpected, ran counter to how resumes were normally filtered, and left me scratching my head about how good people are at making value judgments based on resumes, period. So, I decided to run an experiment.
In this experiment, I wanted to see how good engineers and recruiters were at resume-based candidate filtering. Going into it, I was pretty sure that engineers would do a much better job than recruiters. (They are technical! They don’t need to rely on proxies as much!) However, that’s not what happened at all. As it turned out, people were pretty bad at filtering resumes across the board, and after running the numbers, it began to look like resumes might not be a particularly effective filtering tool in the first place.
Setup
The setup was simple. I would:
- Take resumes from my collection.
- Remove all personally identifying info (name, contact info, dates, etc.).
- Show them to a bunch of recruiters and engineers.
- For each resume, ask just one question: Would you interview this candidate?
Essentially, each participant saw something like this:

If the participant didn’t want to interview the candidate, they’d have to write a few words about why. If they did want to interview, they also had the option of substantiating their decision, but, in the interest of not fatiguing participants, I didn’t require it.
To make judging easier, I told participants to pretend that they were hiring for a full-stack or back-end web dev role, as appropriate. I also told participants not to worry too much about the candidate’s seniority when making judgments and to assume that the seniority of the role matched the seniority of the candidate.
For each resume, I had a pretty good idea of how strong the engineer in question was, and I split resumes into two strength-based groups. To make this judgment call, I drew on my personal experience — most of the resumes came from candidates I placed (or tried to place) at top-tier startups. In these cases, I knew exactly how the engineer had done in technical interviews, and, more often than not, I had visibility into how they performed on the job afterwards. The remainder of resumes came from engineers I had worked with directly. The question was whether the participants in this experiment could figure out who was who just from the resume.
At this juncture, a disclaimer is in order. Certainly, someone’s subjective hirability based on the experience of one recruiter is not an oracle of engineering ability — with the advent of more data and more rigorous analysis, perhaps these results will be proven untrue. But, you gotta start somewhere. That said, here’s the experiment by the numbers.
- I used a total of 51 resumes in this study. 64% belonged to strong candidates.
- A total of 152 people participated in the experiment.
- Each participant made judgments on 6 randomly selected resumes from the original set of 51, for a total of 716 data points1.
If you want to take the experiment for a whirl yourself, you can do so here.
Participants were broken up into engineers (both engineers involved in hiring and hiring managers themselves) and recruiters (both in-house and agency). There were 46 recruiters (22 in-house and 24 agency) and 106 engineers (20 hiring managers and 86 non-manager engineers who were still involved in hiring).
Results
So, what ended up happening? Below, you can see a comparison of resume scores for both groups of candidates. A resume score is the average of all the votes each resume got, where a ‘no’ counted as 0 and a ‘yes’ vote counted as 1. The dotted line in each box is the mean for each resume group — you can see they’re pretty much the same. The solid line is the median, and the boxes contain the 2nd and 3rd quartiles on either side of it. As you can see, people weren’t very good at this task — what’s pretty alarming is that scores are all over the place, for both strong and less strong candidates.
Another way to look at the data is to look at the distribution of accuracy scores. Accuracy in this context refers to how many resumes people were able to tag correctly out of the subset of 6 that they saw. As you can see, results were all over the board.
On average, participants guessed correctly 53% of the time. This was pretty surprising, and at the risk of being glib, according to these results, when a good chunk of people involved in hiring make resume judgments, they might as well be flipping a coin.
Source: https://what-if.xkcd.com/19/
What about performance broken down by participant group? Here’s the breakdown:
- Agency recruiters – 56%
- Engineers – 54%
- In-house recruiters – 52%
- Eng hiring managers – 48%
None of the differences between participant groups were statistically significant. In other words, all groups did equally poorly. For each group, you can see how well people did below.

To try to understand whether people really were this bad at the task or whether perhaps the task itself was flawed, I ran some more stats. One thing I wanted to understand, in particular, was whether inter-rater agreement was high. In other words, when rating resumes, were participants disagreeing with each other more often than you’d expect to happen by chance? If so, then even if my criteria for whether each resume belonged to a strong candidate wasn’t perfect, the results would still be compelling — no matter how you slice it, if people involved in hiring consistently can’t come to a consensus, then something about the task at hand is too ambiguous.
The test I used to gauge inter-rater agreement is called Fleiss’ kappa. The result is on the following scale of -1 to 1:
- -1 perfect disagreement; no rater agrees with any other
- 0 random; the raters might as well have been flipping a coin
- 1 perfect agreement; the raters all agree with one another
Fleiss’ kappa for this data set was 0.13. 0.13 is close to zero, implying just mildly better than coin flip. In other words, the task of making value judgments based on these resumes was likely too ambiguous for humans to do well on with the given information alone.
TL;DR Resumes might actually suck.
Some interesting patterns
In addition to the finding out that people aren’t good at judging resumes, I was able to uncover a few interesting patterns.
Times didn’t matter
We’ve all heard of and were probably a bit incredulous about the study that showed recruiters spend less than 10 seconds on a resume on average. In this experiment, people took a lot longer to make value judgments. People took a median of 1 minute and 40 seconds per resume. In-house recruiters were fastest, and agency recruiters were slowest. However, how long someone spent looking at a resume appeared to have no bearing, overall, on whether they’d guess correctly.
Different things mattered to engineers and recruiters
Whenever a participant deemed a candidate not worth interviewing, they had to substantiate their decision. Though these criteria are clearly not the be-all and end-all of resume filtering — if they were, people would have done better — it was interesting to see that engineers and recruiters were looking for different things.2
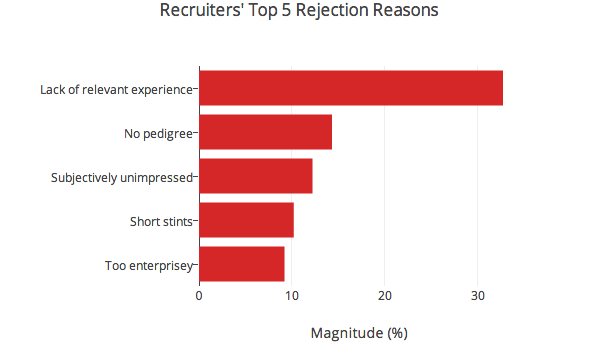
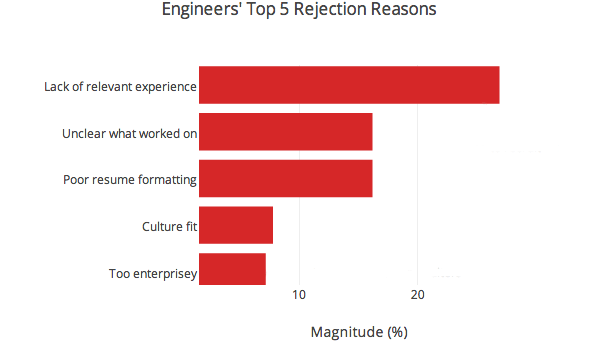
Incidentally, lack of relevant experience didn’t refer to lack of experience with a specific stack. Verbatim rejection reasons under this category tended to say stuff like “projects not extensive enough”, “lack of core computer science”, or “a lot of academic projects around EE, not a lot on the resume about programming or web development”. Culture fit in the engineering graph denotes concerns about engineering culture fit, rather than culture fit overall. This could be anything from concern that someone used to working with Microsoft technologies might not be at home in a RoR shop to worrying that the candidate is too much of a hacker to write clean, maintainable code.
Different groups did better on different kinds of resumes
First of all, and not surprisingly, engineers tended to do slightly better on resumes that had projects. Engineers also tended to do better on resumes that included detailed and clear explanations of what the candidate worked on. To get an idea of what I mean by detailed and clear explanations, take a look at the two versions below (source: Lessons from a year’s worth of hiring data). The first description can apply to pretty much any software engineering project, whereas after reading the second, you have a pretty good idea of what the candidate worked on.


Recruiters, on the other hand, tended to do better with candidates from top companies. This also makes sense. Agency recruiters deal with a huge, disparate candidate set while also dealing with a large number of companies in parallel. They’re going to have a lot of good breadth-first insight including which companies have the highest engineering bar, which companies recently had layoffs, which teams within a specific company are the strongest, and so on.
Resumes just aren’t that useful
So, why are people pretty bad at this task? As we saw above, it may not be a matter of being good or bad at judging resumes but rather a matter of the task itself being flawed — at the end of the day, the resume is a low-signal document.
If we’re honest, no one really knows how to write resumes particularly well. Many people get their first resume writing tips from their university’s career services department, which is staffed with people who’ve never held a job in the field they’re advising for. Shit, some of the most fervent resume advice I ever got was from a technical recruiter, who insisted that I list every technology I’d ever worked with on every single undergrad research project I’d ever done. I left his office in a cold sweaty panic, desperately trying to remember what version of Apache MIT had been running at the time.
Very smart people, who are otherwise fantastic writers, seem to check every ounce of intuition and personality at the door and churn out soulless documents expounding their experience with the software development life cycle or whatever… because they’re scared that sounding like a human being on their resume or not peppering it with enough keywords will eliminate them from the applicant pool before an engineer even has the chance to look at it.
Writing aside, reading resumes is a shitty and largely thankless task. If it’s not your job, it’s a distraction that you want to get over with so you can go back to writing code. And if it is your job, you probably have a huge stack to get through, so it’s going to be hard to do deep dives into people’s work and projects, even if you’re technical enough to understand them, provided they even include links to their work in the first place. On top of that, spending more time on a given resume may not even yield a more accurate result, at least according to what I observed in this study.
How to fix top-of-the-funnel filtering
Assuming that my results are reproducible and people, across the board, are really quite bad at filtering resumes, there are a few things we can do to make top-of-the-funnel filtering better. In the short term, improving collaboration across different teams involved in hiring is a good start. As we saw, engineers are better at judging certain kinds of resumes, and recruiters are better at others. If a resume has projects or a GitHub account with content listed, passing it over to an engineer to get a second opinion is probably a good idea. And if a candidate is coming from a company with a strong brand, but one that you’re not too familiar with, getting some insider info from a recruiter might not be the worst thing.
Longer-term, how engineers are filtered fundamentally needs to change. In my TrialPay study, I found that, in addition to grammatical errors, one of the things that mattered most was how clearly people described their work. In this study, I found that engineers were better at making judgments on resumes that included these kinds of descriptions. Given these findings, relying more heavily on a writing sample during the filtering process might be in order. For the writing sample, I am imagining something that isn’t a cover letter — people tend to make those pretty formulaic and don’t talk about anything too personal or interesting. Rather, it should be a concise description of something you worked on recently that you are excited to talk about, as explained to a non-technical audience. I think the non-technical audience aspect is critical because if you can break down complex concepts for a layman to understand, you’re probably a good communicator and actually understand what you worked on. Moreover, recruiters could actually read this description and make valuable judgments about whether the writing is good and whether they understand what the person did.
Honestly, I really hope that the resume dies a grisly death. One of the coolest things about coding is that it doesn’t take much time/effort to determine if someone can perform above some minimum threshold — all you need is the internets and a code editor. Of course, figuring out if someone is great is tough and takes more time, but figuring out if someone meets a minimum standard, mind you the same kind of minimum standard we’re trying to meet when we go through a pile of resumes, is pretty damn fast. And in light of this, relying on low-signal proxies doesn’t make sense at all.
Acknowledgements
A huge thank you to:
- All the engineers who let me use their resumes for this experiment
- Everyone who participated and took the time to judge resumes
- The fine people at Statwing and Plotly
- Stan Le for doing all the behind-the-scenes work that made running this experiment possible
- All the smart people who were kind enough to proofread this behemoth
1This number is less than 152*6=912 because not everyone who participated evaluated all 6 resumes.
2I created the categories below from participants’ full-text rejection reasons, after the fact.
This study was republished with permission from Aline Lerner.



